Real-Time Motion-Controllable Autoregressive Video Diffusion

Abstract
Real-time motion-controllable video generation remains challenging due to the inherent latency of bidirectional diffusion models and the lack of effective autoregressive (AR) approaches. Existing AR video diffusion models are limited to simple control signals or text-to-video generation, and often suffer from quality degradation and motion artifacts in few-step generation. To address these challenges, we propose AR-Drag, the first RL-enhanced few-step AR video diffusion model for real-time image-to-video generation with diverse motion control. We first fine-tune a base I2V model to support basic motion control, then further improve it via reinforcement learning with a trajectory-based reward model. Our design preserves the Markov property through a Self-Rollout mechanism and accelerates training by selectively introducing stochasticity in denoising steps. Extensive experiments demonstrate that AR-Drag achieves high visual fidelity and precise motion alignment, significantly reducing latency compared with state-of-the-art motion-controllable VDMs, while using only 1.3B parameters.
Motivation
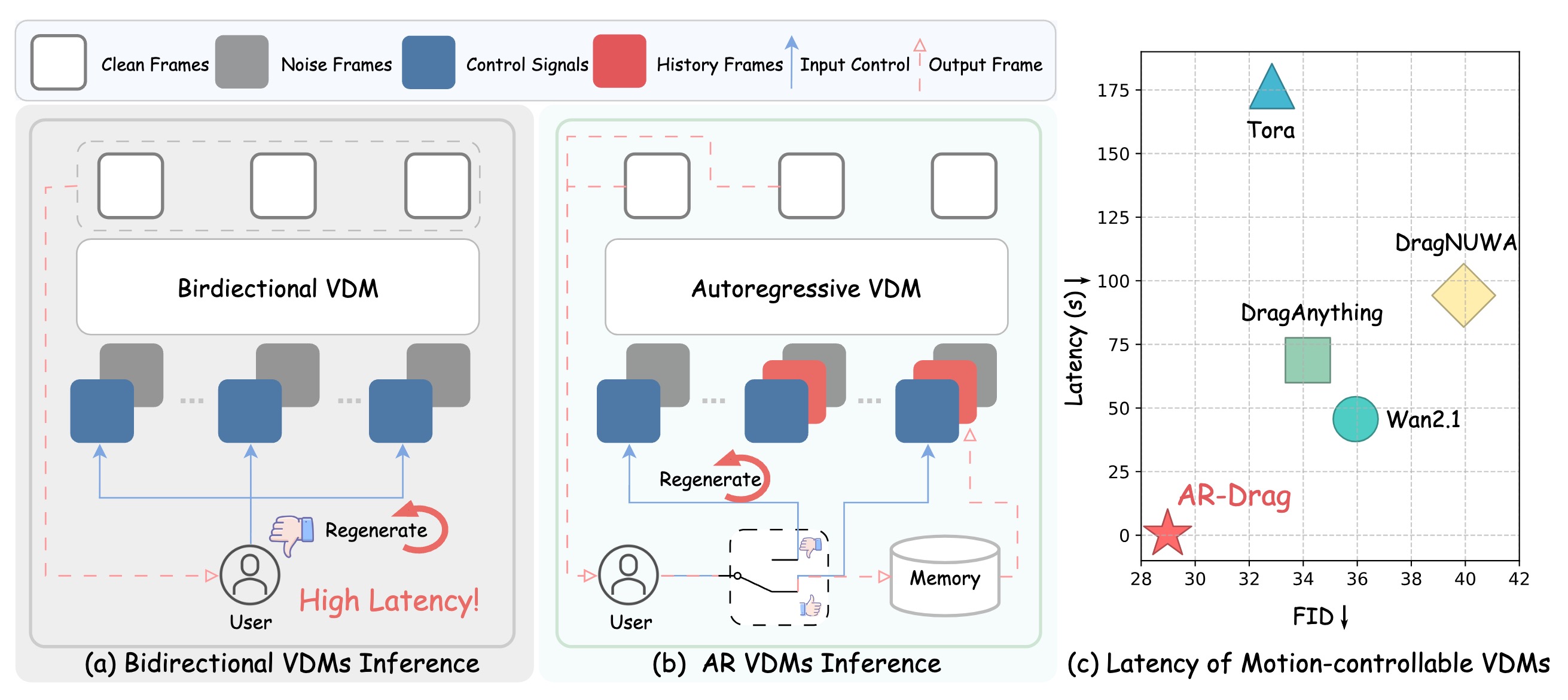
Comparison for motion-controllable video generation. (a) Bidirectional VDMs denoise all frames jointly; motion control can be adjusted only after all frames are generated, causing high latency. (b) In contrast, AR VDMs generate frames sequentially; motion control can be updated frame by frame and, if unsatisfactory, regenerated on the fly, enabling real-time adjustment. (c) Our method achieves significantly lower latency while maintaining superior FID performance.
Pipeline Overview
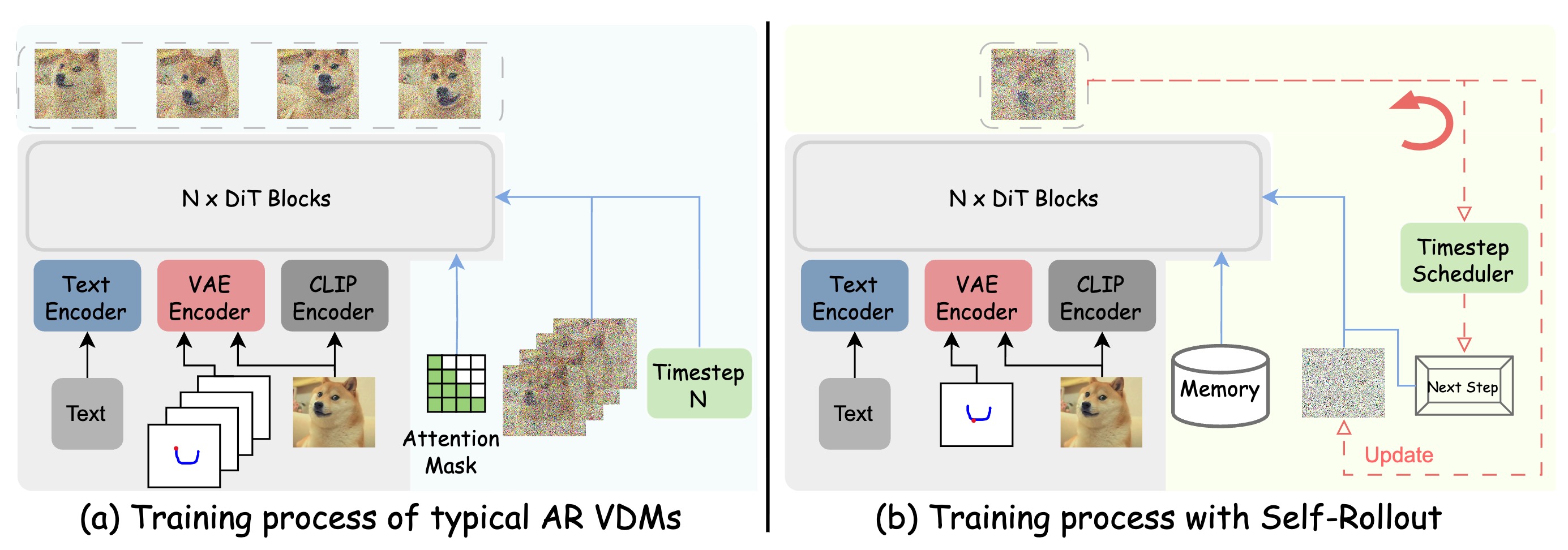
Comparison between typical AR VDMs and Self-Rollout. Self-Rollout faithfully follows the inference process during training, minimizing the train–test gap and naturally preserving the Markov property.
Section I: Comparison aginst baselines
Tora and MagicMotion struggle to maintain consistency with the control signals. Self-Forcing achieves partial controllability but suffers from noticeable deformation and severe quality degradation. In contrast, our method delivers superior fidelity and control alignment.
Section II: Comparison aginst competitive baseline, pretrained backbone and finetuned teacher model.
Our method significantly outperforms the competitive baseline, which suffer from severe quality degradation. In contrast, our model maintains high quality with only slight degradation. The fine-tuned teacher model can be regarded as an approximate upper bound, and our model achieves comparable performance to it. The pretrained backbone exhibits even worse motion consistency due to its lack of explicit motion-control training, further highlighting the effectiveness of our approach.
Section III: Streaming generation with multi input.
Our method supports streaming input, enabling better temporal consistency and higher visual quality. In contrast, bidirectional models—both the pretrained backbone and the fine-tuned teacher model—do not support streaming generation. Therefore, for comparison with these models, we input all control signals jointly during evaluation.